

DataVault is undoubtedly one of the best candidates to consider when it comes time to determine which methodology to adopt in your data architecture. At its core, Datavault offers an agile way to design and create efficient data warehouses.
Hubs could be defined by the central point that integrates the concept of corporate business, which is thus identified by the Business Keys.
Regardless of the existing approach, whether Bottom-Up or Top-Down, the first steps you have to take are very important. The analysis of the information systems must contain all the business concepts, with their business keys identified and one’s must have business value. You can only identify a business concept if it can be understood. In any case, it is vital to do that analysis very well from the beginning.
In the scenarios below, we will dive into some of the various design approaches for DataVault models and the various challenges associated with them. Our end goal is to apply a good design with the correct approach to ensure that our DataVault model is efficient, scalable, and adaptable to our data architecture.
Design Approaches for DataVault Models in Data Architecture
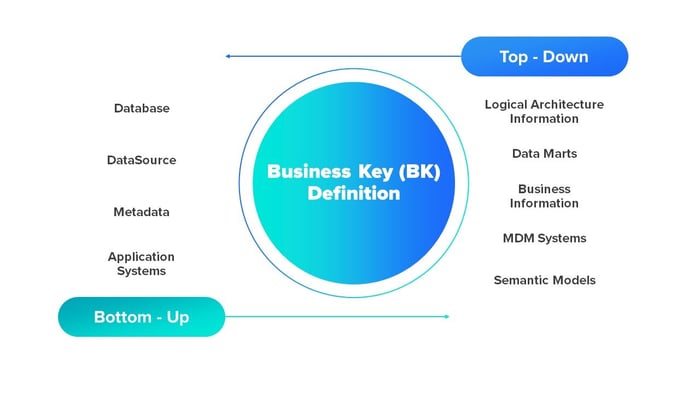
Starting from a brief definition of a model as a group of datasets that conform structured information with one or multiple data domains.
On one hand, the Bottom-Up approach for a DataVault model would apply when trying to faithfully replicate existing information sources. Our DataVault Architecture must be very heterogeneous due to it containing multiple models. So you can imagine that each model will access multiple sources of information with a lot of tables, but it doesn’t mean that we must collect everything! We are only interested in tracing what we are really going to add value to the business! Let’s not forget that.
On other hand, Top-Down approach applies when the business analyzes the corporate business concepts from the different systems / tools available: data marts, MDM, Data Governance and even starts from a Logical Architecture of corporate Information (LAI), which is nothing more than a map of functional information domains by layers, thus going down conceptually to a lower level to reach the business concept. This LAI usually is based on industry reference models but studied and landed for the corporate application. It can also apply for ELM standards to analyze your business.
With this in hand, you predefine your datasets that you want to ingest in our earliest layers of your PSA (Persistent Staging Area) based on the logical information you need. Is for this that you made a process for the intake information from the different sources with that data previously. You don’t replicate the original data sources of information.
In terms of flexibility, the Top-Down case is by nature the case in which it has the least impact for our DataVault model, since the extra layer of preparing the data to a coherent form is outside of this approach,which allows us an even higher level of abstraction, being less susceptible to changes that the sources of origin may suffer.
Now, imagine the unthinkable happens: after crafting a solid and detailed analysis of our company, on both HUBs and satellites in your DataVault models, a corporate Merger event falls upon our Company. You should demonstrate that your Data Architecture is the best place to store all the data together. This is due to it being more scalable, flexible, optimal and with less cost to absorb all the corporate information than the other company.
HUBS — Approach and design
In our scenario cases, we will use a Bottom-Up approach.
Initial Scenario
We are the multinational RETAILER_1 company and this is our process that manage the information of the CUSTOMER business concept in our customer HUB:
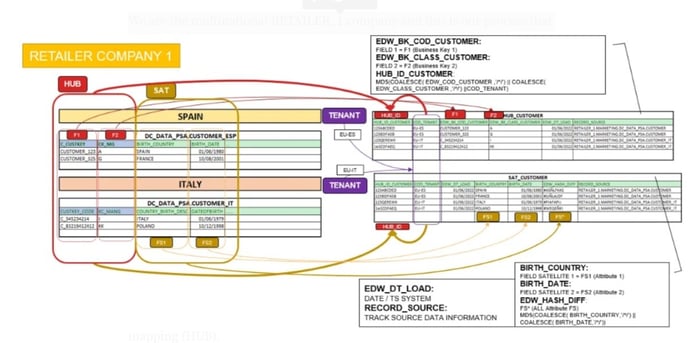
In the previous diagram, we try to explain the different information mappings to load data into our RDV (Raw Data Vault) Architecture. It is defined how each field is generated.
On the left side, we have the PSA/NPSA phases where the different data sources are located. It will apply in the next scenarios in advance. There is an information table for each CUSTOMER country, one for Spain and the other for Italy. Both have a similar format schema and number of fields except for the name of the fields. We will delight in our Business Keys mapping (HUB).
On the right side, we describe the format of our HUB (in RDV):
- HUB_ID_CUSTOMER: Hash ID of the concatenation of the BK (Business Key) + tenants
- COD_TENANT: Multitenant, in this case we only apply a single level, but there can be a Multitenant (more than one level).
- The Business Keys defined like this:
-> EDW_BK_COD_CUSTOMER: Business Key 1
-> EDW_BK_CLASS_CUSTOMER: Business Key 2
- EDW_DT_LOAD: System incorporation date
- RECORD_SOURCE: Track information of our data origin
Changes in the structure of our Business Concept
Although we have already said that a BK must have been analyzed, defined and accepted across the company, on certain occasions what would happen if we cannot avoid it? It is clear that the refactoring scenario is ruled out, DataVault allows us to make our architecture more flexible. Now we have to test our model, and see what scenario we should empower our architecture in the face of both predictable and unpredictable changes.
For such a situation, we analyze what possible scenarios bring us the least possible impact on our architecture. We will observe that the BK schema structure of the new company does not match with the existing one in our DV architecture.
Here I make a point again in which I stress the importance of a good analysis of our company’s business concepts, but even so, it is possible that certain circumstances make our HUBs undergo variations. So our goal will be to build a really robust, efficient and scalable architecture.
We will see the three different scenarios (at the end of this article we will briefly evaluate all together). In the last story in that series, we will do a detailed evaluation.
We will Zoom into the HUB mapping, the Satellite mapping will be the same for all three ones.
SCENARIO Single BK (SBK) — Altering
It is based on the principle of having each BK in one single field.
In this scenario our mission is:
- Incorporate new Tenant Information.
- It will incorporate the new BK in our existing HUB: it will add the EDW_BK_CUSTOMER_TYPE field. Check for the F3 field behavior in the HUB.
In the following figure we show how our new architecture should behave:
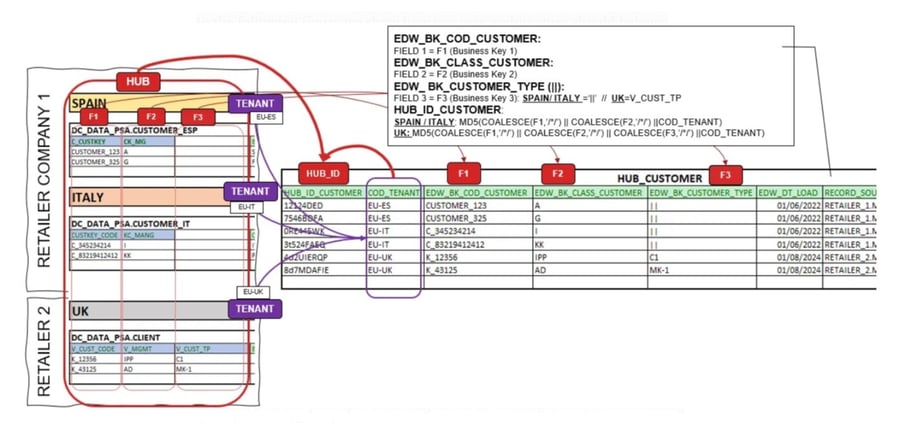
The main challenges for Single BK would be refactoring.
- We will have to refactor on the one side the existing processes, making a treatment informing the default BK.
- We will regenerate the new BK with default values of the already existing information, altering the current physical structure.
- With this approach we will always keep the previous HUB_ID_CUSTOMER, not altering the previous model.
SCENARIO Composed BK (CBK)
It is based on the principle of having all BK in one single field concatenating them in a specific order.
In this scenario our mission is:
- Incorporate new Tenant Information.
- It will incorporate the new BK in our existing HUB: it will manage the new BK information in the current EDW_CBK_CUSTOMER field. It will remain together with the existing ones. Check the F3 behavior flowing into EDW_CBK_CUSTOMER.
In the following figure we show how our architecture should behave:
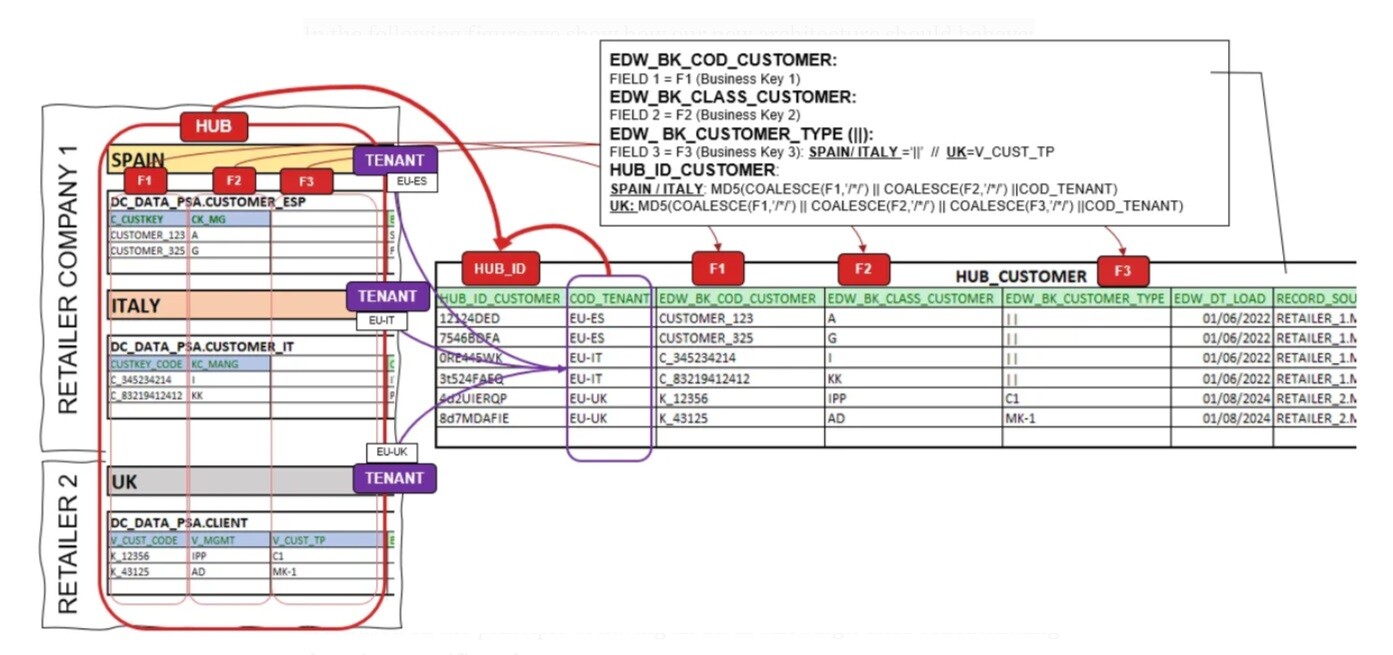
The main challenges of Composed BK will be to sophisticate the methods of access, storing and labeling of the BKs.
- The string, that contains all the business keys, should be taken into consideration to allow us to access the information.
- There will exist a certain heterogeneity of BK in the same field.
- That fact will apply some complexity in order to consume the information by Tenant.
- In addition, it will directly impact our Business Data Vault (BDV), in terms of access performance, governance and understanding of the labeling of the information. I will talk about Refactoring vs Labeling in the next Part.
- So in this way, watch out for the order how you store your BK, it must always be the same one, your process should manage it.
SCENARIO Flexible BK (FBK)
It is based on the principle of having all BK in one single field in semi-structured format. The most common method used is JSON.
In this scenario our mission is:
- Incorporate new Tenant Information.
- It will incorporate the new BK in our existing HUB: it will manage the new BK information in the current EDW_FBK_CUSTOMER field. It will remain together with the existing ones. Check the F3 behavior flowing into EDW_FBK_CUSTOMER.
In the following figure, we show how our architecture should behave:
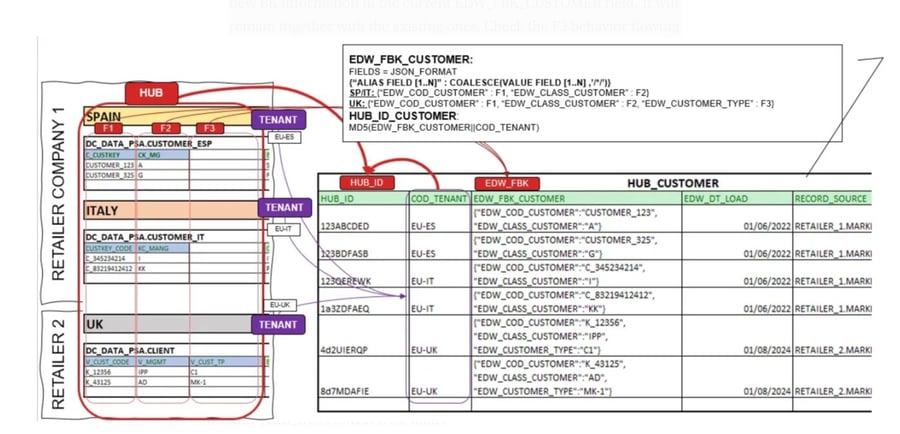
The main challenges of Flexible BK will be to enrich our process with the new BK.
- The current process will add additional complexity, in order to add the new BK in the current semi-structured information by labeling and mapping it.
- We would take into consideration the impact on the performance when you will access the information.
Example of querying BK in our FBK field (in Snowflake). Extract from a dummy HUB_CUSTOMER HUB table:

If we want filter the specific EDW_ID_CUSTKEY (on Snoflake SQL):

Considerations for HUB Scenarios
- Composed BK: It will add some extra complexity in the current information process. The order of the HASH to build your HUB_ID is important.
- Composed BK : It will really affect the performance of access to the information.
- Composed BK / Flexible BK: You also could include the Sequences / Types fields into the field using the same logic in each case.
- Single BK: It will not really affect the performance but it will add a refactoring in our model with the risk associated.
Author:
César Segura
Subect Matter Expert at SDG Group
-1.jpg)
-4.png)




.png)
-1.png)
-2.png)




-1.png)

-1.jpg)
.png)