.png?width=2000&name=SDG%20-%20Logo%20White%20(1).png)

In the wild existing landscape related to the data analytics and machine learning field, Databricks stands out as a powerful and innovative platform to build, deploy, share, and maintain enterprise-grade data, analytics, and AI solutions at scale.

Databricks provides an efficient and collaborative environment for data scientists, engineers, and analysts simplifying the complexity needed for big data processing and analysis as well as machine learning projects.
In this series of articles with a monthly periodicity that we initiate with this one, we will explore different aspects of this tool, starting with its architecture, and following with ways to create workflows to orchestrate data processing, machine learning, and analytics pipelines. Also, we will explore the framework to help teams in the creation of ETL cost-effectively for data quality and error handling, the so-called Delta Live Tables (DLTs). We will continue with the components available on the platform for model governance such as the model registry or the feature store, to finish with the available solution to quickly generate baseline machine learning models, or Databricks AutoML, among other interesting contents.
It will be a long trip, but we promise that it will pay off :). Let’s go!
1. Overview: Databricks, a unified solution for ML and analytics
Databricks lets data scientists, engineers, and analysts collaborate seamlessly with each other while handling tedious backend tasks for them. Roughly, Databricks operates under the so-called control plane and compute plane. These are two layers supporting the functionalities of Databricks.
In general terms, the control plane manages all backend services. It’s where notebooks and many other workspace configurations chill out, encrypted and secured. On the other hand, the compute plane works under the control layer. This is where data gets processed. For example, the compute plane connects Databricks with other services such as an Azure Subscription to use the network configuration and resources already defined there. In other cases, the compute plane can reside inside the Databricks subscription, this is the case for the definition of serverless SQL warehouses or native model serving solutions. Databricks also manages connections with external data sources and storage destinations for batch and streaming data. It’s like having a bunch of vessels that link the platform with the outside world.
This is the main Databricks structure. What is built upon this basis? In the next section, we will explore how these layers are used to shape one big continent. From where the AI/ML solutions are managed, controlled, enhanced, and deployed to the real world.
2. Data intelligent platform: The Pangea from which everything emerges
Let’s start with the formation of a data-intelligent platform. A data intelligent platform is a common place to store massive amounts of structured and unstructured data. The data intelligent platform aims to combine the benefits of classic data warehouses and data lakes. Briefly, data warehouses are built to store structured data ready to be ingested by business insights (BI) applications. Datalakes, in contrast, provide high performance and admit all data types. Classically, datalakes are used after some ETL process has been executed. For example, to provide a storage and consumption solution for ML & AI applications that require several data transformations organized by layers.
Databricks’ data intelligent platform joins all together to mount a unified, open, and scalable data architecture that is built under metadata layers with rich management features. Thus, the data intelligent platform architecture attempts to bridge the gap between the structured and optimized nature of data warehouses and the flexibility and scalability of data lakes.
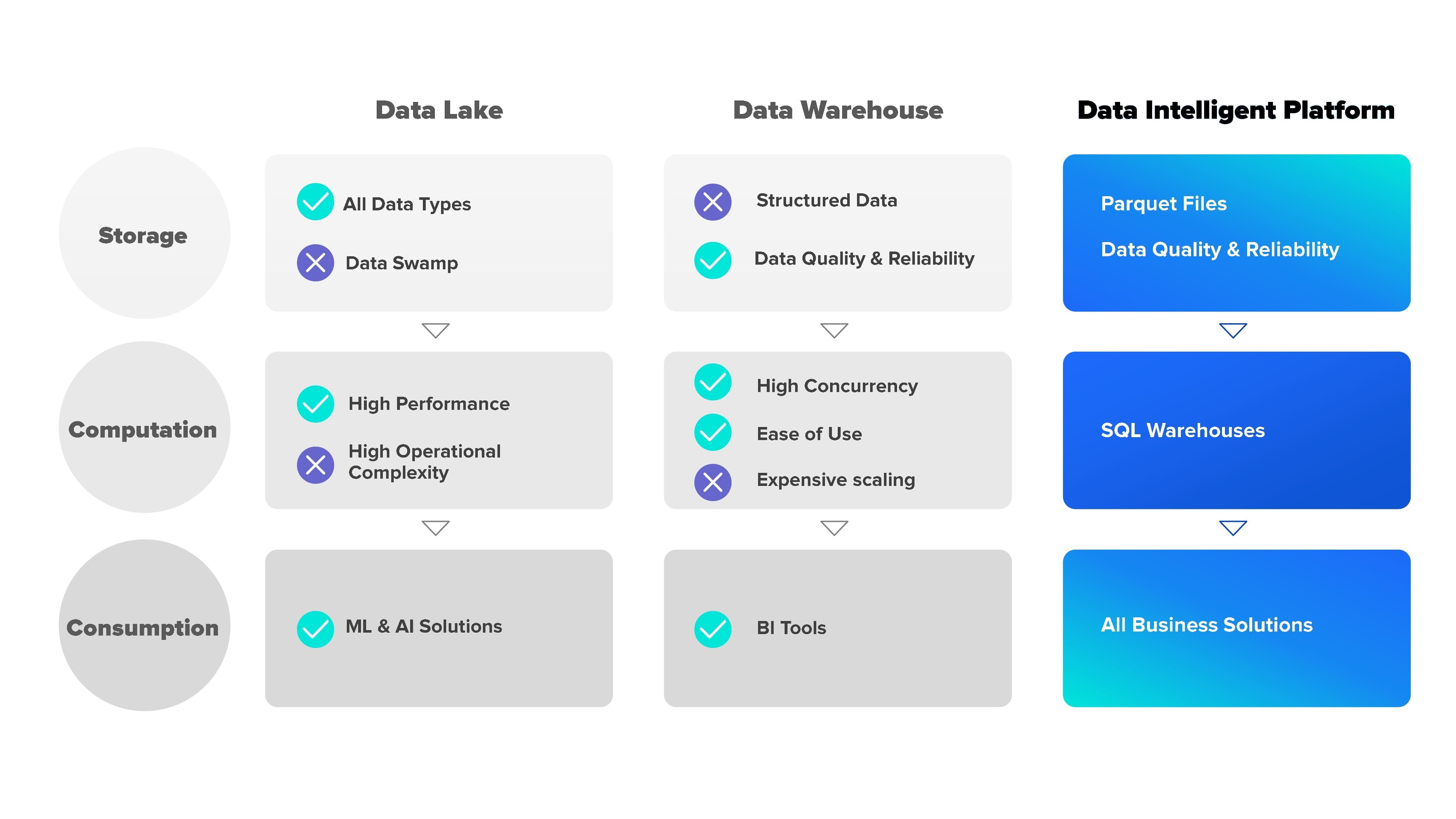
This is illustrated in the above figure. As we can see in the figure, the data is being stored, processed, and consumed in the Data Intelligent Platform for all business solutions. To address the problem of how data is represented, the Data Intelligent Platform makes use of the so-called parquet format, admitting also the computational benefits classically presented in datalakes and data warehouse solutions.
How do Databricks manage to bring the best out of warehouses and data lakes?
Let’s continue with the figures presented in the previous section. Following the rows presented “Storage”, “Computation” and “Consumption”, we will discuss next which benefits Databricks’ Data Intelligent Platform offers compared to the other alternatives:
- Storage: This is possible thanks to the use of parquet files. Apache Parquet is an open-source, column-oriented data file format designed for efficient data storage and retrieval. It provides efficient data compression and encoding schemes with enhanced performance to handle complex data in bulk. Parquet files are also a support for ensuring high levels of quality and reliability to the data stored in the datalake, improving the governance of our data at a columnar level. Apart from parquet files, Databricks’ Data Intelligent Platform storing layer is prepared to support all kinds of data types. Having all the benefits from data warehouses and data lakes in the same place.
- Computation: In terms of computational benefits, Databricks’ Data Intelligent Platform brings the easy operational usability of warehouses and the scalability and high-performance properties of data lakes. This happens thanks to Databricks SQL warehouses: an optimized and elastic SQL compute resources where you just need to pick your cluster size and Databricks automatically determines the best instance types and VMs configuration for the best price/performance. These SQL warehouses are intelligent enough to provide the best possible performance whether we’re dealing with large query performance or high concurrent small workloads.
- Consumption: Now that we have the data stored and processed, it’s time to consume it and extract the business outputs of it. It is here where data lakes win the battle. We’re used to consuming the data in notebooks and with multiple languages and frameworks. Databricks provides a completely enhanced platform to manipulate your data in notebooks with already built-in Data Science libraries, visualization tools, and a connector to your most preferred BI tool.
How do AI/ML solutions benefit from the manner Databricks defines its Data Intelligent Platform?
The Data Intelligent Platform architecture enhances the AI/ML architecture solutions with an optimized ecosystem with already integrated tools presented below as an introduction.
.jpg)
Databricks’ Data Intelligent Platform serves as a ground to build a whole set of features to habilitate complex ML and AI applications on top of it. Next, we list the main ones, but there are others.
- Data Science Workspace & Workflows: Databricks provides Notebooks for Data & Model Exploration. Delta Live Tables enables the building of reliable, maintainable, and testable data processing pipelines. Every asset is managed under the Unity Catalog.
- Data quality in Delta Live Tables: Delta Live Tables introduces expectations clauses, making sure each piece of data passing through queries meets quality standards effortlessly.
- Model Governance & Auto ML: The Unity Catalog takes center stage, offering seamless model governance. In combination with MLFlow, it serves as an all-in-one solution for exploration, model registry, and tracking.
- Data Intelligent Platform Monitoring (ML): Meet the vigilant Data Intelligent PlatformMonitoring platform, your guardian for data quality and ML model performance tracking. It’s a simple, effective way to ensure your insights are top-notch.
We will get deeper into each of these components in the following pills. Pinky promise!
3. Unity Catalog: Now we have continents, how do we govern them?
Unity Catalog is a unified governance solution for data and AI at the Data Intelligent Platform. Unity Catalog will be the main structure where our solution will be built. All of our data, features, models, and pipelines will be stored here. Unity catalog has interoperability with all cloud services and is capable of ingesting data from all these external services. This tool not only brings us the possibility to build a complete solution for A//ML but also provides scalable features for enhanced BI tools that could serve the final client.
Metastore, catalog and schemas
Unity catalog is built under the following structure and components that we will describe below:
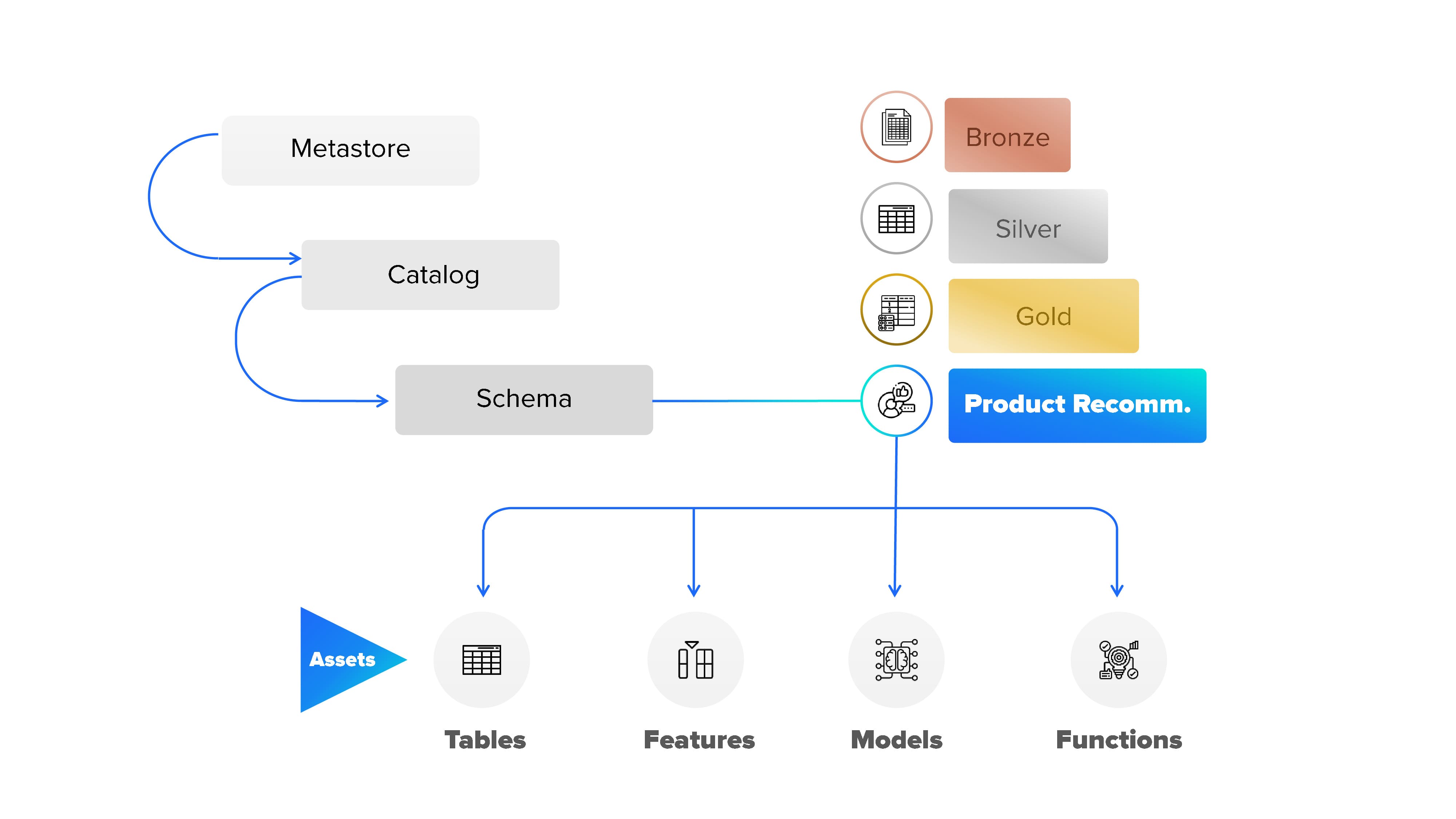
Metastoreacts as a sentinel, safeguarding crucial metadata for data and AI assets. It transcends being a repository, defining access permissions intricately. The catalog, as the foundational layer, orchestrates the meticulous organization of diverse data assets. The schema (databases) contains tables, views, volumes, models, and functions. Thus, schemas are created inside catalogs.
Databricks usually propose the medallion schema structure to organize data inside the datalake separated by layers. It is a data design pattern used to logically organize data in the Data Intelligent Platform. This way, data quality, and data structure are provided incrementally to data when data flows from layer to layer. Thus, we can differentiate between the bronze layer, the silver layer, and the gold layer.
- Bronze Layer: The opening act, where raw data takes the stage, unaltered and pure.
- Silver Layer: A choreographed sequence of analysis and preparation, setting the tone for what follows.
- Gold Layer: The crescendo, extracting new features, crafting data for performance in various business use case scenarios.
Finally, on top of these layers, we can find more specific ones created to give support for a specific business case or scenario. For example, for a product recommendation model that we are building. In this final layer, consolidated data for ML models emerges.
Assets
Within each schema, Functions, Features, Models, and Tables may appear, contributing to a precision-filled performance in data processing and model governance and conforming the main assets related to a business case.
- Tables: Logical group of records stored together in each schema. A schema can contain multiple tables. These tables contain metadata information to ensure proper pipeline structure and transformation. The tables are modified flowing across the transformation pipeline until being used by the ML model.
- Functions: Each schema can contain specific functions that will be frequently used in any possible step of data processing or model governance.
- Features: we consider a feature a specific characteristic of a use case that is measurable and expressed as an alphanumeric variable.Features are usually governed inside Databricks by a feature store. A feature store is a centralized repository that enables data scientists to find and share features and also ensures that the same code used to compute the feature values is used for model training and inference.
- Models: as a model, we’re referring to those already built algorithms that, given some input features, can predict, explain, or give some analytical outputs for the previously commented use case. Models are also usually governed inside Databricks by a model store. A model store is a dedicated hub to store and control the different versions of all models generated for the use case. Models are registered inside the schema to connect data with the artifacts used for analysis. In our case, the models for product recommendation will be registered in a “Product Recommendation” layer created on top of the gold layer.
Here is an example of a Unity catalog structured with a set of tables created for a product recommendation business case for an ML solution:
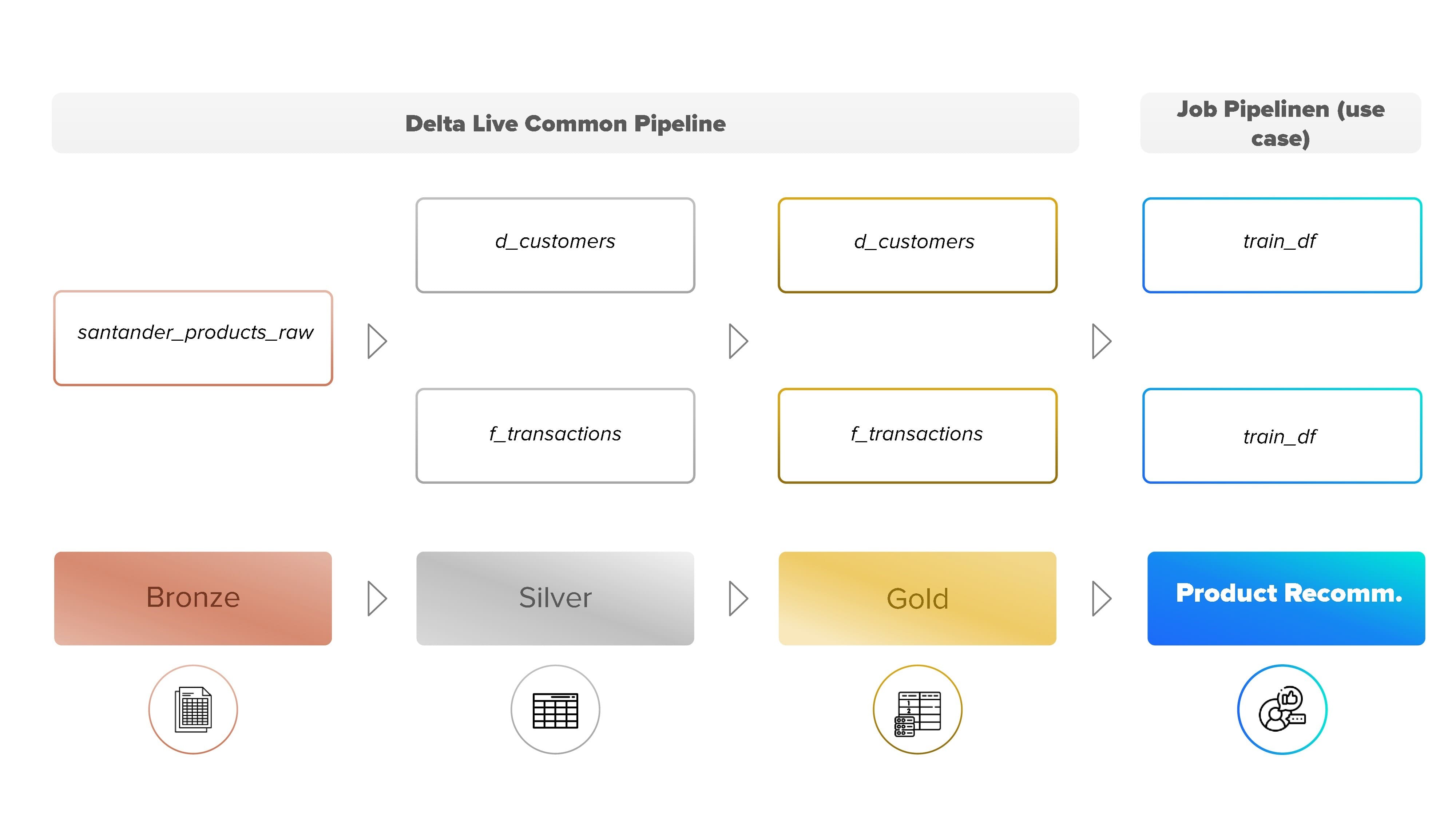
As shown in the figure, the solution is composed of two parts. The first part is in charge of building the medallion architecture seen in a previous section. The final output from this part can be used for multiple business use cases. The second part extracts data from the Gold layer to enrich and prepare this data for its use by a product recommendation model.
4. Delta Lake: The big Delta that joins everything
The term “Delta” comes from the open-source storage layer “Delta Lake”. This storage layer boosts data lakes’ reliability by adding a transactional layer on top of cloud-stored data (AWS S3, Azure Storage, GCS). It supports ACID transactions, data versioning, and rollback capabilities, facilitating unified processing of both batch and streaming data.
In Databricks, we have two main assets using Delta Lake, Delta Tables and Delta Live Tables. Delta Tables is the default table format stored for all tables in Databricks. Delta Live Tables is a vivid version of Delta Tables. The abbreviation used from now on will be “DLT”. We need to think of DLTs as tables with built-in transformation pipelines. This feature improves performance by autoscaling the resources whether we’re working in batches or streaming workloads.
These two features are not the only ones using the “Delta”. Databricks optimizes the queries made to these tables using a Delta Engine by pushing computation to data. Delta Sharing is an open standard used to share data between organizations securely. And to keep track of everything we have DeltaLogs, a place where we could read all the history of our continents.
Conclusion
This article marks the commencement of our exploration into the capabilities of Databricks, a platform that has laid the foundations for our journey. We have introduced fundamental aspects of our metaphorical ship, highlighting its potential as an optimal environment for Machine Learning (ML) and Artificial Intelligence (AI) solutions. Databricks is showcased as a seamlessly integrated solution housed within a singular platform, offering performance, scalability, usability, and reliability.
In the following pills, we will embark on an in-depth investigation, delving into each layer of this integrated framework to unravel the possibilities it presents for advancing ML/AI applications.
References
[Databricks. Overview (Control & Compute Plane)]
[Databricks. (2020, January 30). What is a Data Lakehouse?]
[Databricks. The Data Lakehouse Platform for Dummies]
[Databricks. Delta Lake Guide. Retrieved]
[Databricks. Delta Live Tables Guide. Retrieved]
[Databricks. (2023, October). The Big Book of MLOps, 2nd Edition]
[Doe, J. (2022, January 16). What is a Data Intelligence Platform? Databricks Blog]
Authors:
Gonzalo Zabala
Consultant in AI/ML projects participating in the Data Science practice unit at SDG Group España with experience in the retail and pharmaceutical sectors. Giving value to business by providing end-to-end Data Governance Solutions for multi-affiliate brands. https://www.linkedin.com/in/gzabaladata/
Ángel Mora
ML architect and specialist lead participating in the architecture and methodology area of the Data Science practice unit at SDG Group España. He has experience in different sectors such as the pharmaceutical, insurance, telecommunications, and utilities sectors, managing different technologies in the Azure and AWS ecosystems. https://www.linkedin.com/in/angelmoras/